

En bref :
- Vous pouvez limiter l’impact d’un paywall sur le SEO en changeant votre méthode de blocage bien qu’il y ait d’autres éléments à prendre en compte (possibilité de contournement du paywall et intégrations techniques)
- Google s’adapte de plus en plus au contenu bloqué par un paywall mais il y a quand même des règles à suivre, comme l’utilisation de données structurées pour News et Discover
- Il s’agit de trouver l’équilibre entre une stratégie d’abonnement réussie et un bon référencement donc on vous recommande d’essayer de voir au cas par cas (à chaque article), et d’utiliser différentes stratégies sur votre site (on vous propose 3 façons de limiter l’impact du paywall sur le SEO)
Vous l’avez vu.
Nous l’avons vu.
Les lecteurs l’ont plus que vu.
Les walls sont présents partout 😱
Paywall, Registration Wall, Cookie Wall, ils sont partout.
Il y a quelques années, leur présence était encore limitée aux journaux d’information en ligne qui voulaient réserver tout ou partie de leur contenu payant aux abonnés.
Mais aujourd’hui, leur présence s’est démocratisée.
De plus en plus d’acteurs les utilisent : les publishers (toujours), mais aussi les médias “digital natifs”, les plateformes de e-learning, les broadcasters et même les marques.
Mais, pourquoi sont-ils de plus en plus utilisés 🤔 ?
Tout simplement pour permettre à ces acteurs de transformer leur audience en leads, membres et même en revenus.
Séduisant comme promesse non 🤑 ?
Oui clairement. Et en même temps (👀), on peut légitimement se demander si cette promesse n’est pas sans risque ? Bloquer l’accès au contenu d’un lecteur n’aura-t-il pas des répercussions sur son expérience ? Sur son comportement ? Et par ricochet sur le SEO ?
Aïe. On touche un point sensible. Le SEO.
Un sujet central pour tous les acteurs qui misent sur le contenu pour générer du revenu.
Un asset qui permet de générer beaucoup de revenus (directement ou indirectement).
Alors. Déployer un wall est-ce vraiment une bonne idée ?
Est-ce que ce ne serait pas habiller Paul pour déshabiller Jacques ?
(🤦♂️1970 a appelé, et ils veulent récupérer leurs expressions)
L’expression est nulle, mais la question est intéressante.
Et c’est tout le sujet de livre blanc : comprendre si le déploiement d’un wall impacte le SEO.
Et si on creuse un peu, cette question en amène de nouvelles :
- Quelles sont les différentes méthodes de blocages de contenu qui existent ?
- Quels sont les guidelines en termes de SEO, et l’impact de chacune des méthodes ?
- Quelle est la position de Google sur les paywalls ? Hier, aujourd’hui et demain ?
- Est-il possible de référencer ces contenus soumis à un wall sur AMP, News et Discover ?
- Comment (bien) faire cohabiter wall et SEO ?
- Quelles règles respecter sur une phase de lancement de wall ?
Autant de questions auxquelles nous allons tenter de répondre.
Tenter, oui, car tout évolue très vite et que le sujet du SEO reste un sujet complexe et incertain.
1 - Paywall et méthode de blocage : quel impact sur le référencement d’un contenu
Pour comprendre le sujet dans son ensemble, nous sommes obligés de vous présenter une première partie plus théorique pour comprendre quels sont les types de walls existants, les méthodes de blocages et leur impact sur le SEO.
Si vous connaissez ça sur le bout des doigts, on vous conseille de passer directement à la partie 2 : “Paywall, Registration Wall, Cookie Wall et SEO : comment bien se référencer sur Google ?”
Pour tous les autres, let’s go 👇
Quels sont les différents types de wall ?
Pour simplifier la lecture de cette partie, nous allons présenter les différents types de “paywalls” existants. Mais ce qui s’applique pour les paywalls, s’applique aussi pour les registration walls et les cookie walls.
Freemium : Un modèle de paywall de type “freemium”, est un modèle où certains contenus sont gratuits et accessibles à tous et une autre partie des contenus sont soumis à un paywall et réservés aux abonnés.
Metered : Un modèle de paywall de type “metered”, est un modèle où tous les contenus sont payants, mais où le lecteur a le droit à un certain nombre d’articles en accès libre par semaine ou par mois. À cause de la faible fiabilité du tracking par le cookie, et des possibilités de contournement par les lecteurs, les médias utilisant ces modèles ont généralement enrichi leur metered paywall d’une étape de registration wall dans le parcours utilisateur. Si vous utilisez une méthode de wall “metered”, la question du référencement sera plus simple à traiter.
Hard : Un modèle de paywall de type “hard”, est un modèle où tous les contenus sont payants et réservés uniquement aux abonnés.
Hybride : Un modèle de paywall de type “hybride”, est un modèle qui va mélanger des mécaniques “freemium” et “metered”, avec par exemple des contenus exclusivement réservés aux abonnés, et des contenus en accès libre dans une limite d’un certain nombre par semaine ou par mois.
Ces modèles d’accès au contenu sont les principaux modèles existants. Pour autant, ils ne représentent pas l’ensemble des stratégies présentes chez les médias. Certains médias ont des stratégies d’accès au contenu différentes, avec 3 ou 4 stratégies selon des typologies de contenus différentes, bien que cela reste rare.
Dynamique : On observe une tendance sur les médias à bloquer de plus en plus de contenus pour en réserver l’accès exclusivement aux abonnés (c’est ce que nous montre le Digital Media Review). On sait également que plus la pression du paywall est élevée et plus les lecteurs quittent le site face au paywall (également sur le Digital Media Review :)). Alors comment trouver le juste milieu entre engagement et frustration ? C’est pour répondre à cette question que de nombreux médias déploient des paywalls dynamiques pour adapter leur stratégie de wall selon le contenu, le profil de l’utilisateur, la source. L’objectif ? maximiser le revenu par utilisateur dans son ensemble. Comme ajuster la stratégie de wall selon la propension à s’abonner du lecteur. C’est ce que certains éditeurs ont fait, comme le Wall Street Journal ou encore Le Télégramme.
Alors, comment chaque type de wall impacte mon référencement ? Si vous utilisez une méthode de wall “metered”, la question du référencement sera plus simple à traiter. En effet, si vous laissez accessible un certain nombre de contenus gratuitement à vos lecteurs, Google y aura également accès. Si vous avez un wall de type freemium, hard, dynamique ou hybride, il y aura un certain nombre de règles à respecter pour s’assurer du bon référencement de votre contenu par Google.
 Madeleine White
Madeleine White
Quelles sont les différentes méthodes de blocages utilisées ?
Maintenant que l’on a fait le tour des différents types de walls, il faut que l’on comprenne comment le contenu est bloqué. Pourquoi ? Car cela (peut) impacter directement la stratégie SEO.
Et pour bloquer le contenu, il existe trois méthodes principales.
Les méthodes de blocage “front” ou “côté utilisateur” : Cela signifie que lorsque la page est appelée, le contenu est disponible dans la page, mais qu’il va être masqué et reste non accessible au lecteur. Il existe deux principales méthodes “front” du blocage de contenu.
- Le blocage de contenu via du CSS : La méthode CSS est généralement la méthode la plus simple à mettre en place et c'est celle qui produit le moins d'effets de bords. L’idée est de masquer le contenu en surcouche. Le fonctionnement est généralement le suivant : la <div> article va être masquée selon un % prédéfini, et lors du déblocage, le paywall est retiré, le masquage n’est plus présent et le contenu est visible. Dans cette méthode, le contenu reste entier dans la page et peut être vu en inspectant la page.
- Le blocage de contenu via du Javascript : C’est globalement le même fonctionnement que pour la méthode CSS, à savoir que le contenu va être masqué lorsque l’utilisateur n’a pas accès, puis démasqué lorsqu’il a accès. La principale différence est que le texte ne va pas rester dans la page à proprement parler mais va être caché dans un élément javascript auquel l'utilisateur n'aura pas accès. Ce qui peut poser d’éventuels problèmes de conflits avec certains formats publicitaires ou éditoriaux in-script
Les méthodes de blocage “back” ou “côté serveur” (sans optimisation SEO) : Contrairement au mode de blocage côté front, et comme son nom l’indique, le blocage du contenu va s’effectuer côté serveur. Cela signifie que le contenu complet n’est jamais envoyé dans la page. Dans la majorité des cas 2 pages existent côté serveur : une page complète et une page “croppé”. Par défaut c’est la page croppé qui est envoyée, et lorsque l’utilisateur a les droits pour accéder au contenu, une page complète est envoyée à l’utilisateur de manière dynamique. Cette méthode de blocage, comme nous l’expliquerons, est la plus sûre, mais c’est également celle qui est la plus complexe à mettre en œuvre et qui peut, si elle n’est pas bien maîtrisée, avoir le plus d’impact sur le SEO, étant donné que le contenu, en dehors du chapô, n’est pas disponible dans la page.
Pour un blocage côté serveur, si aucune manipulation technique n’est faite, les lecteurs auront accès uniquement au chapô de l’article, tout comme Google. Par conséquent, c’est uniquement cette partie qui sera référencée.
Les méthodes de blocage “back” ou “côté serveur” (avec optimisation SEO) : le principe est le même qu’expliqué ci-dessus concernant le blocage du contenu. La seule différence va résider dans le fait de laisser le contenu accessible au Google Bot. Soit en laissant passer le user agent Googlebot, soit via la méthode des données structurées.
LeMonde.fr a testé une méthode de ce type (qui n’est plus live aujourd’hui) qui consistait à envoyer l’article complet quand le user agent était Googlebot pour optimiser le référencement. Sur le principe cela permettait d’afficher une page complète pour le Google Bot, mais croppé et donc non contournable au lecteur lambda.
Malheureusement, cela restait contournable, et c’est probablement la raison pour laquelle ils ont arrêté. En effet, si vous affichez une page complète côté navigateur, votre contenu reste plus facilement accessible. Dans ce cas de figure, des extensions de contournement de paywall comme “Bypass Paywalls” qui vont utiliser toutes les méthodes connues pour appliquer des possibilités de contournement de paywall. C’était le cas pour LeMonde.fr où l’extension switchait automatiquement votre user agent pour celui de Google Bot.
Avantages et inconvénients de chaque méthode de blocage
L’avis de l’expert : Simon Gleize - consultant SEO : “Si vous ne devez retenir qu’une et une seule règle à respecter pour bien référencer vos contenus soumis à un wall, c’est celle-ci : que le contenu soit rendu accessible à Google sans que cela puisse passer pour du cloaking".
Alors quelle est la bonne solution ? Un blocage côté utilisateur ou côté serveur ?

Et bien, au risque de vous décevoir, il n’existe pas UNE bonne réponse.
Cela va dépendre de nombreux critères liés à votre stratégie et votre business model :
- Votre business model est il dépendant à 10% de revenus indirects ou 90% ?
- La stratégie payante est-elle un axe central de votre stratégie ?
- Votre audience est-elle susceptible de connaître les méthodes de contournement ?
C’est donc à chaque éditeur de définir quelle méthode de blocage choisir.
Loin de nous l’idée de vous laisser sans réponse 😁. Alors pour vous permettre d’y voir un peu plus clair, voici quelques grands principes.
Vous pouvez privilégier une méthode de blocage côté front (au moins au début) si :
- Vous avez une grosse dépendance publicitaire ;
- Votre audience n’est pas susceptible de connaître les méthodes de contournement ;
- Vous avez des doutes sur l’impact SEO de la méthode côté serveur ;
- Vous lancez une stratégie paywall / registration wall et souhaitez faire quelques tests.
Vous pouvez privilégier une méthode de blocage côté serveur si :
- Vous avez une bonne compréhension des implications SEO ;
- Vous avez de gros enjeux de sécurité et de protection de vos contenus ;
- Vous avez une audience très au fait des méthodes de contournement.
L’avis de l’expert : Alexandre Santini - CPO chez Poool : “Les éditeurs ont tendance à privilégier le blocage côté front car l’expérience à démontrée qu’une majorité d’utilisateurs ne cherchent pas à passer outre. Nous savons aussi que ceux qui cherchent une faille ne convertissent pas. A mon sens, le blocage côté serveur est plus à corréler avec des enjeux de business (abonnement disposant d’un prix elevé par exemple)”, d’audience (si le titre parle de cybersécurité par exemple) ou d’image."
Bonus : un listing (non exhaustif) des méthodes de contournement des walls
🎁 En bonus, nous vous avons préparé une liste (non exhaustive) des méthodes existantes à l’heure actuelle pour contourner les paywalls.
Les méthodes de contournement “à la main” : Ces méthodes vont nécessiter une action de l’utilisateur au niveau de la page, soit en supprimant un élément de la page, soit en supprimant une fonctionnalité (ex : javascript), soit en inspectant des éléments de la page. On retrouve par exemple :
- Suppression du CSS ;
- Modification du CSS (ex : Le Parisien) ;
- Suppression du Javascript ;
- Inspecter le code source de la page ;
- Et accéder au cache de Google (version texte) si la balise noarchive n’est pas insérée. (En savoir plus ici)
Les méthodes de contournement par des extensions disponibles sur les navigateurs : Dans ce cas-là, on va retrouver des extensions ou des fonctionnalités natives des navigateurs qui pour la plupart vont scrapper le HTML, et donc faire sauter les éléments CSS ou jS de la page, pour créer une lecture “zen”. On peut retrouver par exemple :
- Le mode lecture Zen sur Safari et Firefox F9 ;
- Les extensions navigateurs comme Mercury Reader.
Les méthodes de contournement par des extensions non disponibles sur les navigateurs : Il existe des extensions, qui ne sont pas référencées sur les stores d’extensions que ce soit pour Chrome ou Firefox, mais qui sont disponibles par exemple sur Github, et qui peuvent s’installer en mode développeur. On peut penser par exemple à
- Bypass Paywalls ;
- Unpaywall.
Les créateurs de ces extensions connaissent généralement très bien les méthodes de contournement des paywalls, et testent de les appliquer sur les principaux médias, puis stockent les méthodes qui fonctionnent et les mettent à jour avec les retours de leurs communautés.
Focus sur le contournement par les adblockers : Le contournement par les adblockers est sujet particulier et technique. En effet un paywall peut être bloqué par un adblocker dans 2 cas particuliers et distincts :
- La solution de paywall (le partenaire) a son script qui est bloqué par une liste d’adblocker (Ablock+, uBlock, ..) ou encore une liste de privacy comme Disconnect, la liste utilisée par Firefox. Si le script est bloqué, alors le paywall ne s’affichera pas.
- Le paywall appelé via un gestionnaire tag peut être bloqué par les listes d’adblockers. GTM (Google Tag Manager) est par exemple bloqué par uBlock. Par conséquent si le script est appelé à travers GTM, alors l’appel du script sera bloqué et le paywall ne sera pas affiché.
😱😱😱 Mon wall est contourné, est-ce grave docteur ?
Il est intéressant de voir que Le New York Times par exemple privilégie des méthodes de blocage de contenu côté utilisateur en javascript, qui sont, comme nous l’avons vu ci-dessus, largement contournables et contournés par certains.
Pourquoi ? Nous n’avons pas la réponse mais on peut imaginer 3 raisons :
- La flexibilité permise par les méthodes côté utilisateur ;
- Le faible impact et risque sur le SEO ;
- Mais aussi et surtout parce que les utilisateurs qui contournent le paywall du New York Times ne sont pas LA cible n°1, ce ne sont pas ceux qui vont s’abonner à court et moyen terme.
Et comme on peut le voir avec leurs résultats, ce choix d’accepter le contournement ne semble pas impacter fortement la croissance d’abonnement numérique sur le digital.
 Madeleine White
Madeleine White
2 - Paywall, Registration Wall, Cookie Wall et SEO : comment bien se référencer sur Google ?
Maintenant que nous avons une meilleure compréhension des méthodes de blocage et leur impact sur le référencement, il nous faut nous attaquer au coeur du problème :
Est-ce que les différents types de wall, même avec des méthodes de blocage “SEO friendly”, peuvent avoir un impact négatif sur le SEO ?
Autant vous avertir dès maintenant, vous ne trouverez pas de réponses définitives dans les lignes qui vont suivre. Pour la simple et bonne raison qu’il n’y en a pas.

Le SEO étant par nature un sujet sur lequel nous ne connaissons pas toutes les composantes, il est donc impossible d’affirmer avec certitude et précision l’impact dans la durée d’un paywall sur une stratégie SEO.
Ces prochaines lignes, en revanche, doivent vous permettre de vous forger votre propre opinion et vous donner des pistes pour minimiser les risques.
Quelle est la position de Google par rapport aux contenus payants ?
Pour comprendre les risques à long terme des walls sur le SEO, il nous faut absolument faire un retour en arrière sur le positionnement de Google (toujours délicat) sur le sujet.
Et oui ! A partir du moment où le sujet des walls est devenu un enjeu pour les médias, Google a dû se positionner. Et plus le sujet devient central et plus la position de Google évolue.
On vous laisse voir ça 👇
2005 : First Click Free. Google a introduit en 2005 la logique du first click free, qui comme son nom l’indique, devait permettre à un lecteur en provenance de Google Search de bénéficier gratuitement des contenus, même si ceux-ci étaient payants. L’objectif annoncé par Google était “d’offrir” la possibilité aux éditeurs d’être découvert dans Google News et Google Search. Tout est expliqué sur leur blog :
“The spirit of the First Click Free effort was - and still is - to help users get access to high quality news with a minimum of effort, while also ensuring that publishers with a paid subscription model get discovered in Google Search and via Google News.”
2009 : First Click Free limité à 5 articles. En 2009, les modèles payants se développent et les éditeurs ont peur que certains lecteurs abusent du “first click free spirit”. Le SEO est aussi important pour les éditeurs, que le contenu des éditeurs l’est pour Google. Naturellement, Google s’adapte et propose, suite à une mise à jour, de limiter le first click free à 5 articles.
2015 : First Click Free limité à 3 articles. Il faut comprendre qu’en 2015, la part de “gros” éditeurs américains avec un modèle payant et donc un paywall est plus importante que la part d’éditeurs sans. Le sujet est vrai aux USA, mais s’accélère dans tous les pays. Le sujet de l’accès au contenu payant devient un enjeu central, et assez naturellement, pour les raisons évoquées ci-dessus, Google change à nouveau ces règles et passe abaisse la limite à 3 articles.
2017 : Goodbye First Click Free. Hello Flexible Sampling. En 2017, Google, dans un article écrit par Richard Gingras (VP News chez Google) et intitulé “Driving the future of digital subscriptions” (le ton change), annonce la fin du First Click Free. Ce ne serait finalement plus à Google de décider combien d’articles doivent être gratuits pour les lecteurs en provenance de Google Search, mais bien aux éditeurs eux-mêmes de décider ce qu’il paraît être le bon niveau d’articles à offrir :
“We will end our First Click Free policy in favor of a Flexible Sampling model where publishers will decide how many, if any, free articles they want to provide to potential subscribers based on their own business strategies. This move is informed by our own research, publisher feedback, and months-long experiments with the New York Times and the Financial Times, both of which operate successful subscription services.”
Le point le plus important dans cette déclaration est la mention “publishers will decide how many, if any, free articles”. Le flexible sampling aurait pu porter à confusion sur le bon nombre de contenu à offrir. Mais finalement offrir un contenu, bien que fortement recommandé par Google, n’est pas obligatoire.
Il est d’ailleurs précisé par Google dans un article sur son blog que 2 modèles de flexible sampling existent :
- Le metered : qui permet à un lecteur de consulter un certain nombre d’articles gratuitement avant d’être bloqué et de devoir s’abonner ;
- Le lead In : qui permet à un lecteur de lire les premières lignes d’un article, puis le reste du contenu est bloqué et le lecteur doit s’abonner pour lire le contenu en entier.
Alors, comment (bien) référencer ces contenus bloqués sur Google ?
Comme nous l’avons vu précédemment, il faut appliquer la méthode du flexible sampling, que ce soit le metered, ou le lead-in pour référencer ces contenus payants sur Google.
Sur le papier ça à l’air très simple, mais concrètement est-ce la seule chose à faire ? N’y a t’il pas d’autres règles à respecter ?
Et bien si, et ce n’est pas si simple 🤯
Il y a effectivement un certain nombre de règles à respecter. Et ce n’est pas toujours la même chose selon le format : search, AMP, Google News, Discover, …
C’est ce que nous allons essayer de comprendre ensemble.
Comment bien référencer les contenus bloqués sur Google
En plus du choix de la méthode de blocage, et des règles de Google sur les contenus derrière un wall, il existe d’autres règles pour bien référencer son contenu.
L’avis de l’expert: Simon Gleize, consultant SEO: “Si vous ne devez retenir qu’une et une seule règle à respecter pour bien référencer vos contenus soumis à un wall, c’est celle-ci : que le contenu soit rendu accessible à Google sans que cela puisse passer pour du cloaking.
(PS : On a tellement adoré la citation de Simon, qu’on s’est senti obligé de la mettre 2 fois.)
En effet, une des problématiques des contenus bloqués cachés derrière un wall, est qu’ils peuvent être considérés comme du cloaking. Le "cloaking" est une pratique qui consiste à présenter aux internautes des URL ou un contenu différent de ceux destinés aux moteurs de recherche. Cette pratique constitue une infraction aux Consignes aux webmasters de Google, car elle propose aux internautes des résultats différents de ceux attendus. Ce qui peut être le cas dans le cas d’un contenu premium ou bloqué car dans le cas du flexible sampling par lead in, le contenu affiché à l’utilisateur est tronqué alors que celui affiché au Googlebot est potentiellement accessible en entier.
Pour contourner cette problématique, Google propose d’utiliser les données structurées et de suivre les 3 étapes suivantes :
- Ajoutez un nom de classe autour de chaque section de la page soumise à un paywall.

2. Ajoutez des données structurées NewsArticle.
3. Ajoutez les données structurées liées au paywall dans le JSON-LD NewsArticle.

Nota Bene : JSON-LD et le format de microdonnées constituent les méthodes acceptées pour la rédaction de données structurées pour le contenu soumis à un paywall.
L’ensemble de ces éléments est clairement expliqué dans un article sur la documentation de Google. Notamment le cas d’éditeurs qui ont plusieurs sections soumises à paywall au sein d’une même page.
Une fois que les données structurées sont en place, vous avez 2 possibilités :
- Référencer uniquement la section de l’article accessible par le “lead in”. Dans ce cas-là, vous n’avez rien de spécifique à faire ;
- Référencer la totalité de l’article, y compris la section soumise à un paywall. Dans ce cas-là, vous avez tout intérêt à vérifier que votre page est indéxée par Googlebot.
Si vous privilégiez l’option 2, le référencement de votre contenu, va également dépendre de la méthode de blocage de contenu que vous avez choisi.
Si vous utilisez une méthode de blocage côté front/utilisateur en CSS ou Javascript, vous n’avez pas de manipulation supplémentaire à faire car le contenu est disponible dans la page. Si vous utilisez une méthode de blocage du contenu côté serveur, on vous conseille de relire la partie 1 de ce livre blanc pour voir comment optimiser votre référencement avec ce type de blocage.
Enfin, comme vous vous en doutez, il faudra également s’assurer que le contenu peut être indexé et exploré par Google (pas de blocage de Googlebot et Googlebot-News dans le fichier robots.txt)
L’avis de l’expert : Julien PICOT - Technical SEO Lead chez Oncrawl : Pour assurer le référencement de contenus bloqués, l'important est de laisser Google voir l’ensemble du contenu présent : celui sur la page ainsi que celui derrière le paywall. En ayant accès à la globalité du contenu, Google pourra alors comprendre si la page est pertinente par rapport à un sujet donné. Grâce aux données structurées, on signale à Google quelle partie du contenu est accessible à tous, et quelle partie se situe derrière le paywall. Cette indication est importante, sinon cela peut-être assimiler à du ‘cloaking’. Enfin, pour s’assurer que son crawler voit le site de la même manière que Google, il faudrait white-lister l’IP de son crawler.
“Ok pour la partie “search”. Mais est-ce possible de mettre un wall sur contenu AMP ?
AMP veut littéralement dire “Accelerated Mobile Pages”. C’est une technologie développée par Google qui a pour objectif de délivrer le contenu plus rapidement sur mobile.
C’est un format que vous trouverez (principalement) sur mobile lors d’une requête sur Google. Dans les premiers résultats plusieurs “cards” seront visibles comme résultat de recherche, et lorsque vous cliquez sur une card, vous pouvez naviguer d’une card à l’autre en “swipant”. Le format AMP est utilisé dans d’autres contextes, mais celui-ci est le plus connu.

Bonne nouvelle : Il est tout à fait possible de déployer un paywall sur les contenus AMP, pour réserver certains contenus à vos membres ou à vos abonnés. Il conviendra entre autres d’utiliser le composant AMP-Access pour gérer le blocage de votre contenu.
Nota Bene : chez Poool nous avons développé notre propre composant pour gérer l’accès au contenu. Comme vous pouvez l’imaginer, il s’appelle AMP-Access-Poool, et il vous permet de déployer un paywall dynamique sur vos contenus AMP.
Si vous décidez de publier vos contenus sur AMP, voici quelques précautions à respecter, directement préconisées par Google :
- “Assurez-vous que votre point de terminaison d'autorisation permet aux robots appropriés de Google et d'autres entreprises d'accéder au contenu. Les méthodes varient en fonction de l'éditeur.”
- “Assurez-vous que votre règle d'accès pour les robots est la même pour les pages AMP et standards. Dans le cas contraire, des erreurs de type "Le contenu ne correspond pas" peuvent s'afficher dans la Search Console.”
Le conseil de l’éditeur : Alexy Souciet - SEO Manager - CMI France :
"Si vous sortez une version payante sur la version desktop, soyez prêt également à sortir une version payante sur l’AMP
(si vous avez une version AMP correspondante). Si vous ne le faites pas, vous pouvez rencontrer 2 problématiques :
Cas n°1 : vos contenus sont bloqués sur la version desktop mais pas sur AMP où ils seront accessibles gratuitement. Dans ce cas-là, on se posera la question de la cohérence d’un tel modèle.
Cas n°2 : vos contenus sont bloqués sur la version desktop mais vous n’êtes pas prêt sur la version AMP. Vous décidez alors de “désactiver” les contenus AMP. Vous risquez une chute du trafic AMP, pas tout le temps contre balancée sur desktop. Si vous ne tardez pas trop, à la réactivation de vos contenus premiums sur AMP, vous retrouverez « généralement » votre niveau d’audience."
“Google News et Discover sont des leviers important de trafic pour nous. Quel est l'impact du paywall sur la reprise des contenus par Google News et Discover”

Excellente question que l’on entend souvent.
Et la réponse est : oui cela semble possible !
Si vous respectez les règles expliqués dans la partie “Référencer ces contenus payants pour Google Search”, vous devriez pouvoir référencer vos contenus sur Google News. A une petite exception près, il faut vous adapter les différentes règles utilisées pour Googlebot-News en plus de Googlebot.
“Et pour Discover ?”

D’abord, discover, qu’est-ce que c’est ? Google Discover est un flux d’actualité personnalisé. L’objectif est simple, comme nous l’explique Google : “Discover new information and inspiration with Search, no query required”. Ce produit, qui existe en réalité depuis 2016 avant d’avoir été “re-brandé”, est présent dans un certain nombre d’applications et produits Google, plus ou moins nativement (l’application Google, Google Chrome, nativement sur certains téléphones Android, ..).
On comprend tout de suite la puissance de frappe d’un tel outil, au vu de son adoption native par de nombreux utilisateurs, sans nécessairement l’avoir voulu. C’est une incroyable source de trafic et la possibilité d’atteindre une nouvelle audience. Preuve du potentiel, un nouvel onglet “Discover” a fait son apparition dans la Google Search Console depuis mi 2019.
Comme pour Google News, on peut se demander comment bien référencer ces contenus payants sur Discover ? Est-ce possible ? Et quelles sont les règles à respecter ?
L’avis de l’expert - Simon Gleize : consultant SEO : ‘“Il n'y a pas de règles clairement établies qui permettent de garantir la présence d'un article dans Google News ou Discover. Mais on constate quand même que de plus en plus d'articles paywallés sont repris. D'ailleurs les récentes évolutions de Google (Google News Showcase, Suscribe with Google...) montrent que Google prend en compte l'évolution du modèle économique de la presse en ligne, de plus en plus tourné vers l'abonnement."
Rassurant, non ?
Même s’il n’y a pas de règles officielles, certains acteurs spécialistes du SEO éditent tout de même certaines bonnes à pratiques à respecter pour maximiser ces chances d’apparaître.
On a également demandé à un de nos clients de nous donner son avis.
Là aussi, c’est rassurant.
Le conseil de l’éditeur : Alexy Souciet - SEO Manager - CMI France :
"Sur Elle.fr, le passage au payant, sur nos contenus issus de notre stratégie « chaude », n’a pas été un frein à la visibilité sur la box Actu, Google News et Discover. A noter que nous sommes dans une configuration de blocage front, sans déclaration du balisage HTML / JSON qui se trouve dans les guidelines de Google."
Et, même si c’est possible de le faire, est-ce une bonne idée de référencer ses contenus payants sur News et Discover ?
C’est une bonne question. On peut effectivement se poser la question de la stratégie de wall à mettre sur ces supports (news, discover), sur lesquels les lecteurs vont être par nature plus “volatiles”. La mise en place d’un paywall dynamique prend tout son sens ici car elle peut vous permettre d’adapter la stratégie de wall selon le contexte. Par exemple, proposer un registration wall sur les contenus AMP, ou une offre d’essai 24H gratuite ? Tout ceci est possible avec notre solution de wall dynamique Poool Access. Réservez une démo gratuite ou contactez-nous !
3 - Wall et SEO : est-ce risqué à long terme ? Comment limiter les risques et maximiser les chances de réussite ?
Peut-on être sûr, même si l’on suit toutes les pratiques recommandées par Google, que les paywalls ne vont pas avoir un impact négatif important à moyen/long terme sur le SEO ?
Comme vous l’avez compris en lisant les précédentes parties, il est tout à fait possible d’avoir une stratégie de blocage du contenu (paywall, registration wall, …) et limiter les impacts SEO à court terme. On sait qu’il est tout à fait possible de maîtriser ce que Google “voit” et donc optimiser cette partie-là.
Pour autant, si demain vous décidez de bloquer de plus en plus de contenus sur votre site, comment le comportement des lecteurs va impacter le référencement de vos contenus payants ?
Le Digital Media Review, nous a montré que pour les médias avec des modèles payants, plus les contenus payants étaient visibles et plus cela avait un impact positif sur la conversion (jusqu’à une certaine limite), MAIS à contrario que cela avait un impact négatif sur les taux de départs du site face au wall.
En partant de ce constat, un responsable SEO peut se poser de nombreuses questions.
- Si la part de contenus payants devient trop importante et que le taux de lecteur qui quitte le site face au paywall explose, comment cela va impacter le SEO ?
- De la même façon, on peut imaginer que pour les mêmes raisons, le linking pourrait être moins important pour les contenus payants que les contenus gratuits ?
Et la liste de questions peut s’allonger facilement.
On peut donc légitimement se demander : est-ce que les walls ont une incidence négative sur le SEO à long terme ?
Prenons quelques exemples
Prenons par exemple le cas du New York Times. Ils ont mis en place une stratégie payante depuis maintenant 10 ans, avec un haut niveau de frustration pour ces lecteurs (un registration wall au bout du 2ème article lu, et même parfois au 1er).
Pour autant, ils arrivent tout de même à bien se référencer dans la durée en étant aujourd’hui :
- Top 50 US ;
- Top 100 Monde ;
- Avec plus de 32.75% du trafic en provenance du Search.
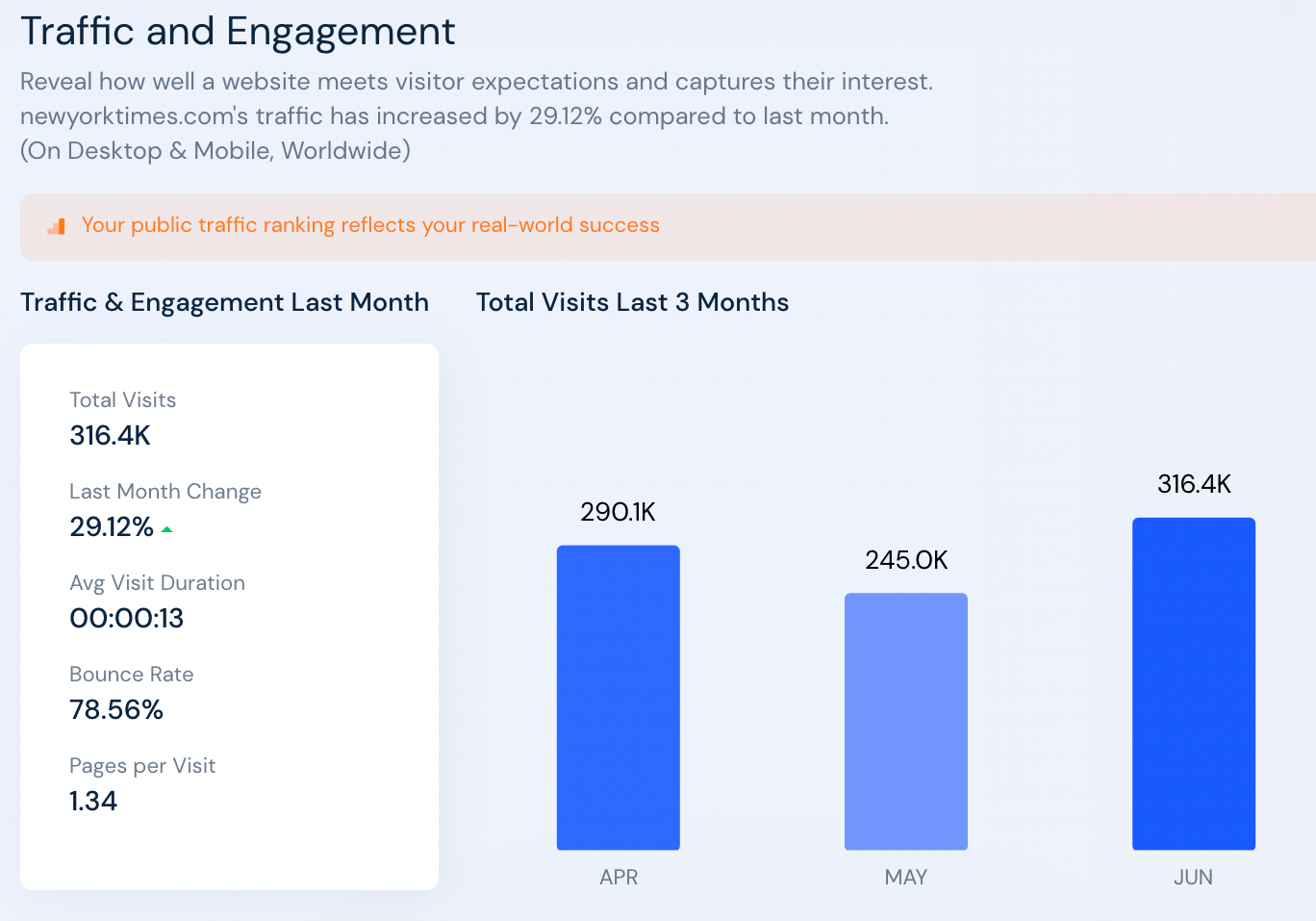
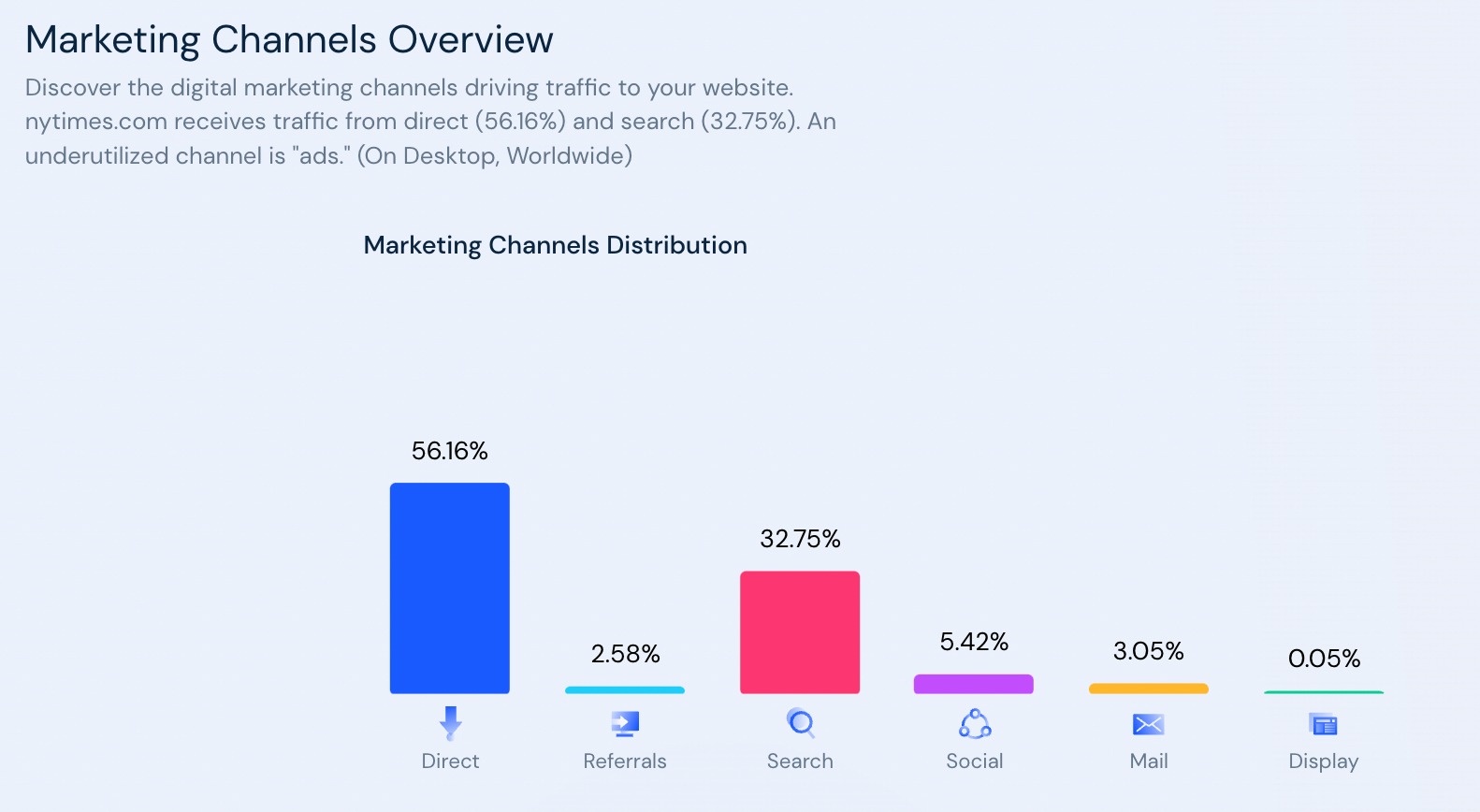
Nota Bene : Ces chiffres sont de mêmes à prendre avec des princettes, car on ne sait pas sur cette part de trafic en provenance du search :
- Quelle est la part d’accès direct “déguisée” (requêtes “NYT” ou New York Times” sur le moteur de recherche) ;
- Quelle est la part de trafic liée à des articles et / ou à des pages spécifiques ;
- Et comment cela a évolué entre aujourd’hui et il y a 20 ans.
Attention, plus on creuse, et plus les choses se compliquent.
Car les les avis et les exemples d’éditeurs sont également contradictoires.
Dan Smullen, qui s’occupe du SEO pour Independent News & Media, a réalisé plusieurs tests pour mesurer l’impact du paywall sur le référencement des contenus (cet exemple est présenté sur un article du blog CXL)
- 1er test - déployer un registration wall :
Avant de lancer notre paywall en février, nous avons mis en place un soft wall - un "registration wall". Nous l'avons testé sur deux répliques totalement temporaires de nos sites pour le Canada et l'Australie. Pour les utilisateurs de ces pays, nous avons placé tout le contenu derrière un "registration wall". Nous avons constaté une baisse de moins de 5 % du trafic sur une période de six mois, mais un nombre considérable de nouvelles inscriptions.
- 2ème test - déployer un paywall sur des contenus evergreen et bien référencés :
"Nous avons également testé la mise en place d'un "registration wall" sur 50 % des pages de notre rubrique "voyages" (avec une position moyenne de 1 à 5 dans la Google Search Console sur une période de 3 mois). Nous avons sélectionné la rubrique voyages d’Independent.ie en raison de son classement pour les requêtes à caractère permanent, telles que "choses à faire au Canada". Nous n'avons constaté aucune baisse significative du classement moyen. À l'heure actuelle, Independent.ie est toujours numéro 1 sur Google.ie en Irlande, même s'il se trouve derrière un paywall."
Au final, peu ou pas d’impact d’un point de vue SEO, et un impact business très positif.
Et, en même temps, si vous écoutez Barry Adams (expert SEO) de Polemic Digital, vous aurez une réponse légèrement nuancée : "Si Google doit choisir entre un élément de contenu soumis à des restrictions et un élément de contenu gratuit qui présentent à peu près les mêmes critères de qualité, il classera toujours le contenu gratuit en premier, car il offre une meilleure expérience utilisateur."
Ces deux avis sont très intéressants.
Et il faut rajouter à cette équation (avec beaucoup d’inconnues) le fait que Google ne peut pas non plus s’opposer définitivement à une tendance de fond dans les médias : la montée en puissance des walls et des modèles payants. Si tous les contenus gratuits sont valorisés dans l’algorithme, la pertinence des contenus proposés au lecteur va s’en voir dégrader également. Google doit également trouver un juste milieu, et fait des ajustements en permanence.
Vous l’aurez donc compris. A la question : “lancer un wall, est-ce risqué pour mon SEO”, vous n’obtiendrez ici, et ailleurs, aucune réponse définitive.

Et étant donné que l’on n’aura pas la réponse, peut-être faut-il poser la question différemment.
Après tout, les éditeurs qui mettent en place des stratégies de walls, le font dans un objectif bien précis : développer une base de membre, acquérir des abonnés digitaux, etc... Il y a donc une logique business.
Lancer un wall va, par essence, avoir un impact, positif et négatif, sur les a sources de revenus d’un média.
Peut-être faut-il se poser la question suivante : comment limiter le risque SEO tout en maximisant la valeur créée par les walls ?
Hum. Cela paraît simple comme ça. Mais comment faire concrètement ?
Possibilité n°1 - Limiter l’impact SEO d’un wall en adaptant la méthode de blocage selon le contenu
Nous l’avons vu dans la partie 1, le choix de la méthode de blocage (côté utilisateur ou côté serveur) et le type de paywall (metered vs hard) peut avoir une incidence sur votre SEO.
Alors, plutôt que de choisir une méthode qui s’applique pour tous les contenus, certains éditeurs essayent de prendre le meilleur de chacune des méthodes. C’est le cas par exemple d’un de nos clients : Gamekult. Ils utilisent un paywall hybride freemium + metered, avec 2 méthodes de blocage du contenu. Blocage côté serveur pour les contenus exclusifs, et blocage côté front via un metered pour les contenus à risque SEO fort.
Possibilité n°2 - Limiter l’impact SEO d’un wall en adaptant la stratégie selon la typologie de contenu
Cas n°1 - Je lance un wall sur une nouvelle catégorie de contenu
Si vous souhaitez vous positionner sur des contenus très concurrentiels sur lesquels vous n’avez aucun historique aujourd’hui, est-ce vraiment une bonne idée de bloquer tout de suite ces contenus derrière un paywall ou un datawall ?
2 raisons à ça :
- Pour votre SEO (et toutes les raisons expliquées ci-dessus) ;
- Une deuxième raison, plus stratégique : si vos lecteurs ne connaissent pas votre expertise, votre légitimité sur une thématique, pourquoi s’abonneraient-ils ?
Si pour autant, vous souhaitez tout de même intégrer un wall tout de suite sur cette nouvelle catégorie de contenu, nous vous conseillons :
- De respecter toutes les guidelines de Google présentes dans ce livre blanc ;
- De bien suivre et monitorer la part de contenus derrière un wall ;
- Et de faire beaucoup de tests ! Par exemple, en bloquant certains contenus et d’autres non comme l'a fait le groupe Independent News & Media (Nous allons revenir sur ce point par la suite).
De la même façon, si vous importez vos contenus du print pour les passer en payant, il peut être important de vérifier avant s’il n’y a pas un contenu déjà bien référencé sur le même sujet, sans quoi vous pourriez avoir un impact négatif sur celui-ci.
Cas n°2 - Je lance un wall sur une catégorie de contenu existante
Si vous êtes dans cette situation, faites attention aux contenus “froids”, encore plus si vos concurrents sont positionnés sur la même thématique; mais en gratuit.
Ce sont des contenus pour lesquels vous avez beaucoup investi, et qui pourraient à moyen/long terme être impacté par la mise en place d’un wall. Et s’il y a un impact, vous risquez de mettre beaucoup de temps pour retrouver vos positions.
Certains éditeurs nous ont remonté des pertes sur ce type de contenu suite à la mise en place d’un wall, alors que leur visibilité était stable pendant plusieurs années. A contrario, si vous positionnez votre wall sur des contenus “chauds” pour lesquels vos concurrents sont eux aussi positionnés avec un paywall, alors le risque est bien moindre.
Alors à la question “lancer un wall, est-ce risqué pour mon SEO” ? On peut répondre :
Oui dans certains cas et selon la façon dont c’est fait. Mais que, s’il y a un risque, celui peut être limité au minimum, tout en maximisant les chances de réussite de votre stratégie de wall (création de compte, abonnement).
L’objectif est donc de penser ça de manière globale.
Possibilité n°3 - Limiter l’impact SEO d’un wall en adaptant la stratégie selon le risque SEO d’un contenu
Tout est question d’arbitrage.
Lorsqu’on regarde les objectifs d’un média dans son ensemble, on peut noter :
- Faire venir des lecteurs ;
- Les engager ;
- Les monétiser ;
- Collecter de la donnée ;
- Convertir les lecteurs en membre ou en abonné ;
- Fidéliser les lecteurs, et limiter le churn.
De la même façon que certains lecteurs vont permettre d’atteindre certains objectifs (tous vos lecteurs ne deviendront pas abonnés), vos contenus n’ont pas tous été faits dans le même but, et peuvent vous permettre d’atteindre différents objectifs : Attirer, engager, convertir et fidéliser les abonnés. À chaque contenu son objectif !
Nos équipes vous proposent un arbre décisionnel à destination des éditeurs pour les aider à choisir quel contenu doit être payant quel contenu doit être gratuit. Bien entendu, chaque rédaction peut et doit l’adapter à son contexte pour tomber au plus juste de son modèle de revenus. Voici à quoi cela ressemble :

Et, pour en savoir plus, vous pouvez consulter notre article dédié :
Marion Wyss
Lors de la rédaction de ce livre blanc, et lors de nos échanges avec différents experts SEO, nous nous sommes aperçus que cet arbre de décision pouvait être adapté aux enjeux SEO d’un média. Avant de passer un contenu en payant, il faut probablement se poser quelques questions supplémentaires :
- Est-ce que le risque SEO est faible, moyen ou fort ?
- Est-ce que l’impact business (engager, convertir, rétention) est faible, moyen ou fort ?
Et ensuite il faut arbitrer :
- Si un contenu a un risque SEO faible (ex: contenu chaud où les concurrents sont avec un wall) et une forte probabilité de nous permettre d’atteindre nos objectifs, alors il n’y a pas de contre-indications à le passer en payant.
- Par contre si l’impact business est faible et que le risque SEO est fort (contenu evergreen avec concurrence en gratuit), alors il faut probablement se poser 2 fois la question de passer le contenu derrière un wall.
Donnons la parole aux experts
Nous avons voulu vous apporter un éclairage sur le sujet en interrogeant des experts et en leur demandant leurs bonnes pratiques pour réussir le déploiement de leur stratégie de wall et limiter l’impact SEO.
Voici leurs réponses :
Le conseil de l’éditeur : Alexy Souciet - SEO Manager - CMI France: J’étais de cet avis, au début. Dans le cas d’une stratégie « froide », avec la difficulté à se positionner sur certaines requêtes à fort volume de recherches, qui plus est si l’on est dans un univers de concurrence « gratuit » (ce qui n’arrange rien), on a tout de suite en tête que rajouter un paywall va anéantir totalement nos chances.
Tout simplement parce que cette « frustration » créée par le paywall, à niveau d’optimisation égale (édito, linking, technique) pourrait jouer en notre défaveur notamment au niveau des signaux UX.
De manière empirique, je constate qu’il peut y avoir des surprises (voir anecdote).
Quelques conseils pour limiter l’impact :
- Ne pas basculer d’inventaire existant et important pour l’audience SEO en payant.
- Dans un premier temps pour la production, avoir un arbitrage gratuit / payant via un arbre de décision en ajoutant la dimension SEO (= avec notion de potentiel de trafic)
- Attention tout de même à ne pas « laisser que les miettes » aux contenus payants >> vers une cohabitation du SEO et du payant.
- Y aller progressivement et étape par étape en test & learn
Point de vigilance : Quand on jongle avec 2 modèles, celui historique « publicitaire » et « payant », je pense qu’on doit rester en alerte sur la cannibalisation entre les contenus, les nouvelles pratiques journalistiques d’écriture, de linking interne, titraille, optimisations sémantiques qui pourraient venir « saboter » le travail SEO qui peut être fait à côté.
Je termine sur une petite anecdote avec un comportement qu’on était loin d’imaginer au départ !
Ci-dessous, un contenu taillé pour performer dans les SERPS, mais derrière un paywall. Avec essentiellement une concurrence gratuite, il obtient tout de même la « position 0 ». Etant donné que nous sommes dans une configuration où Google « voit tout le contenu », il n’a pas de problème à extraire le contenu pour alimenter la réponse. Nous voilà piégé par notre propre stratégie…

Le conseil de l’éditeur : François Chauvin - Head of acquisition B2C - Welcome to the Jungle:
Quelle précaution pour limiter le risque ? : Les recommandations de Google sont très claires sur ce sujet. ainsi, si elles sont suivies à la lettre, il n'y a pas lieu de s'inquiéter a priori d'une quelconque pénalité. On pourrait penser à juste titre que Google n'allait plus voir uniquement qu'une partie du contenu de l'article sur lequel le paywall est affiché. Google décrit précisément dans ses guidelines la méthode schema.org JSON-LP à utiliser sur son site pour éviter toute perte de positionnement.
La mise en place de données structurées simples et spécifiques (NewsArticle, isAccessibleForFree...) vous permettra de bien notifier à Google votre stratégie et de ne pas perdre le positionnement de vos articles. Il convient néanmoins d'étudier de près les facteurs d'expérience utilisateur sur vos articles afin de déterminer si cette expérience a été dégradée ou non et si potentiellement cela peut avoir un impact à moyen terme sur votre visibilité SEO, la satisfaction de vos lecteurs et la qualité de votre contenu.
Quels outils pour monitorer l'impact ? : Il convient déjà de déterminer quel est le KPI principal que vous souhaitez suivre ainsi que les KPIs secondaires. Il me semble essentiel de comparer de manière précise tous les indicateurs UX : taux de rebond, temps passé sur le site, nombre de pages vues pendant la session afin de voir l'impact de l'intégration du paywall sur l'expérience de vos utilisateurs. Il vous faudra aussi comparer les comportements des utilisateurs en fonction de leur provenance (SEO, réseaux sociaux, newsletter par exemple) afin de déterminer si des schémas, messages ou autres actions peuvent être adaptés pour une meilleure utilisation de vos services.
Le KPI principal reste évidemment le nombre de membres généré par l'activation d'un paywall. Il est ensuite essentiel de pouvoir déterminer le gain généré par ce membre vs un non-membre (visites et pages vues supplémentaires, inscriptions supplémentaires sur des services associés, candidatures sur des offres d'emploi...etc).
4 - Wall & SEO, se lancer sans risque, possible ?
Vous êtes un éditeur et vous lancer une stratégie paywall, registration wall ou cookie wall ?
Faites la politique des petits pas. Cela ne vous permettra peut-être pas d’atteindre un risque 0, mais de limiter l’impact sur votre SEO, et au passage de maximiser les chances de réussite de votre projet de wall.
1 - Choisir quels contenus mettre derrière un wall
Tout d’abord il vous faut décider quels sont les contenus gratuits et payants. Et pour chacun d’entre vous poser la question des contenus à risque côté SEO :
- Est-ce que risque SEO est faible, moyen ou fort ?
- Est-ce que l’impact business (engager, convertir, rétention) est faible, moyen ou fort ?
Si le risque est fort et l’impact business faible, il faut probablement les écarter des stratégies de wall (on vous recommande de lire notre section précédente sur le sujet :)).
2 - Choisir la bonne méthode de blocage
Bien sûr, choisir sa méthode de blocage, comme nous l’avons expliqué dans la partie 2 est propre à chaque média. Pour autant, sauf dans certains cas très spécifiques, nous vous recommandons de privilégier une méthode de blocage côté front.
Pourquoi ? 4 raisons :
- C’est plus simple à mettre en place ;
- C’est plus “SEO friendly” qu’une méthode de blocage côté serveur (sans optimisation technique SEO);
- Sauf cas spécifique, le risque de contournement est faible et l’impact sur le business le sera aussi ;
- Et si vous bloquez côté utilisateur et vous estimez finalement le risque fort, basculez sur une méthode de blocage côté serveur. Dans ce sens la c’est plus logique, plutôt que l’inverse, ou vous allez faire de gros développements pour au final revenir à quelque chose de simple.
Notre meilleur argument (malheureusement) c’est de vous dire que le New York Times utilise une méthode de blocage côté front. Probablement pour les mêmes raisons que celles évoquées précédemment.
Nota Bene : vous pouvez aussi choisir un modèle hybride comme le fait notre client Gamekult (certains contenus à forte valeur bloqués côté serveur, et d’autres à moins forte valeur ajoutée côté front).
3 - Respecter les consignes de Google et tester que tout est OK
On vous recommande de relire notre partie 2, qui présente comment bien se référencer dans tous les “environnements” Google : AMP, News, Discover …
Une fois que vous avez compris les bonnes pratiques et que vous avez mis les règles qui vont bien en place. On vous conseille de faire un check de la bonne implémentation des guidelines de Google. Et pour ça, 2 outils sont à vos dispositions :
- Google Search Console et l'outil d'inspection d'URL
- Google’s Structured Data Testing Tool
4 - Faites des tests pour limiter les risques
Si vous décidez de lancer un wall sur votre site, et que vous avez des doutes sur l'impact pour votre SEO, le choix de la méthode de blocage, ... alors faites des tests !
Déployez le wall sur un contenu, une catégorie, pour commencer.
Puis regardez dans un premier temps si ces contenus sont référencés. Et dans un second temps s’ils sont bien référencés, et si la mise en place du wall n’impacte pas votre positionnement.
Puis une fois que vous vous êtes fait votre propre idée, vous pouvez accélérer progressivement.
Conclusion
"Est-il possible de lancer un wall (Paywall, Registration Wall, Cookie Wall) sans impacter mon SEO ?"
Comme vous l'avez-vu dans ce livre blanc, nous n'avons aujourd'hui pas la possibilité d'affirmer qu'il est possible de lancer une stratégie de wall sans impacter son SEO.
Certains pensent que oui. D'autres que non.
Certains chiffres montrent que non. D'autres que oui.
🤯🤯🤯
Etant donné que nous n'aurons jamais une réponse 100% certaine à cette question, il est préférable d'attaquer ce sujet sous un autre angle : comment faire cohabiter wall et SEO ?
Et c'est tout le sens que nous avons voulu donner à ce livre blanc, vous donner le contexte pour comprendre les enjeux, et ensuite mettre en place une stratégie qui correspondra à vos enjeux et aux éventuels risques sur votre business.
Et oui, car si vous lancez un wall, c'est probablement dans un objectif bien précis :
- Développer l'acquisition d'abonnés ;
- Augmenter ma base d'inscrits ;
- Optimiser mon taux de consentement ;
- Etc ...
Et si vous déployez un wall il est possible que ça ai un impact positif sur votre objectif business, mais peut être un impact négatif sur d'autres indicateurs (par exemple les revenus publicitaires).
Il faut donc se demander si le déploiement d'un wall permet d'augmenter les revenus au global. Impact sur le SEO ou non.
Si vous impactez légèrement le SEO mais développez fortement vos revenus, alors le pari est gagné, et l'enjeu sera de limiter l'impact du wall sur le SEO.
Cela parait simple comme ça, mais être capable de répondre à la question "le déploiement d'un wall permet-il d'augmenter les revenus au global" est loin d'être un sujet simple. Il nous faut avoir une vue du revenu dans son ensemble, ne pas opposer publicité et abonnement, SEO et accès direct, mais penser global. Penser revenu par utilisateur.
Tout cela semble assez lointain d'ici, mais sera la norme dans les prochaines années avec l'arrivée du poste de Chief Revenue Officer dans les entreprises.
Madeleine White Marion Wyss
Marion Wyss Maxime Moné
Maxime Moné